 |
Zihan Ding丁子涵zhding96@gmail.com / zihand@princeton.edu Google Scholar / GitHub / Twitter / CV / Research Gate |
About Me
Zihan Ding is Research Scientist at Bytedance Seed Multimodal & World Model team. He achieved the Ph.D. degree at the Electrical and Computer Engineering Department, Princeton University, supervised by Chi Jin. He obtained an MSc in Machine Learning with Distinction from Imperial College London in Fall 2019. He previously worked with Dr. Edward Johns at the Robot Learning Lab at Imperial for his thesis project.
Before the MSc, he received two Bachelor degrees from the University of Science and Technology of China in 2018, majoring in Photoelectric Information Science and Engineering (Physics Dept., Bachelor of Science) and dual-majoring in Computer Science and Technology (CS Dept., Bachelor of Engineering). His bachelor thesis was supervised by Dr. Jinming Cui and Prof. Yunfeng Huang.
He has conducted research at Meta GenAI/MSL MovieGen team (Menlo Park), Adobe Research (San Jose), Meta Fundamental AI Research (FAIR, New York), Inspir.ai (Beijing), Tencent Robotics X (Shenzhen), and Borealis AI (Toronto).
Research interests: His research goal is Artificial General Intelligence with long-term planning capabilities, potentially with Consciousness. This breaks down into sequential decision-making problems and expressive models with generalization. Consequently, his interests predominantly revolve around reinforcement learning with function approximations (deep RL) in single-agent or multi-agent scenarios (with game-theoretical insights), world models with expressive diffusion generative models, foundational multi-modal models, and learning-based methods for robotics with generalization capability.
"Research is about intellectual pilgrimage when climbing the mountain of persent knowledge, self-talking, acquiring deep and structral understanding, capturing the flash of inspiration, quick prototyping, persuing rigorism, simplicity and beauty."
Blogs
- Side Project: Arbitrage at Crypto Market with Optimal Profit (2023.05)
- Foundational Video World Model (2024.12)
- Nuts and Bolts in Training Transformers and Diffusion Models (2025.04)
- A Review of My Last 10 Years of Study and Research (2025.09)
- Conscious AI Agents and Alignment (2025.09)
- Shall We Build AI Decently? (2026.01)
- Side Project: Artalor, an Agentic Framework for Long Video Creation (2026.05)
Publications
| Books | |
| Deep Reinforcement Learning: Fundamentals, Research and Applications
Hao Dong, Zihan Ding, Shanghang Zhang Eds. Springer 2020 ISBN 978-981-15-4094-3, 1st ed. [Homepage][eBook][Amazon][中文版] | |
| 机器学习系统:设计与实现(Machine Learning System: Design and Implementation)
Luo Mai, Hao Dong, et al 清华大学出版社 Tsinghua University Press 2022 ISBN. Author of Chapter: Reinforcement Learning System [Homepage] | |
| Selected Papers | |
| Recurrent Autoregressive Diffusion: Global Memory Meets Local Attention
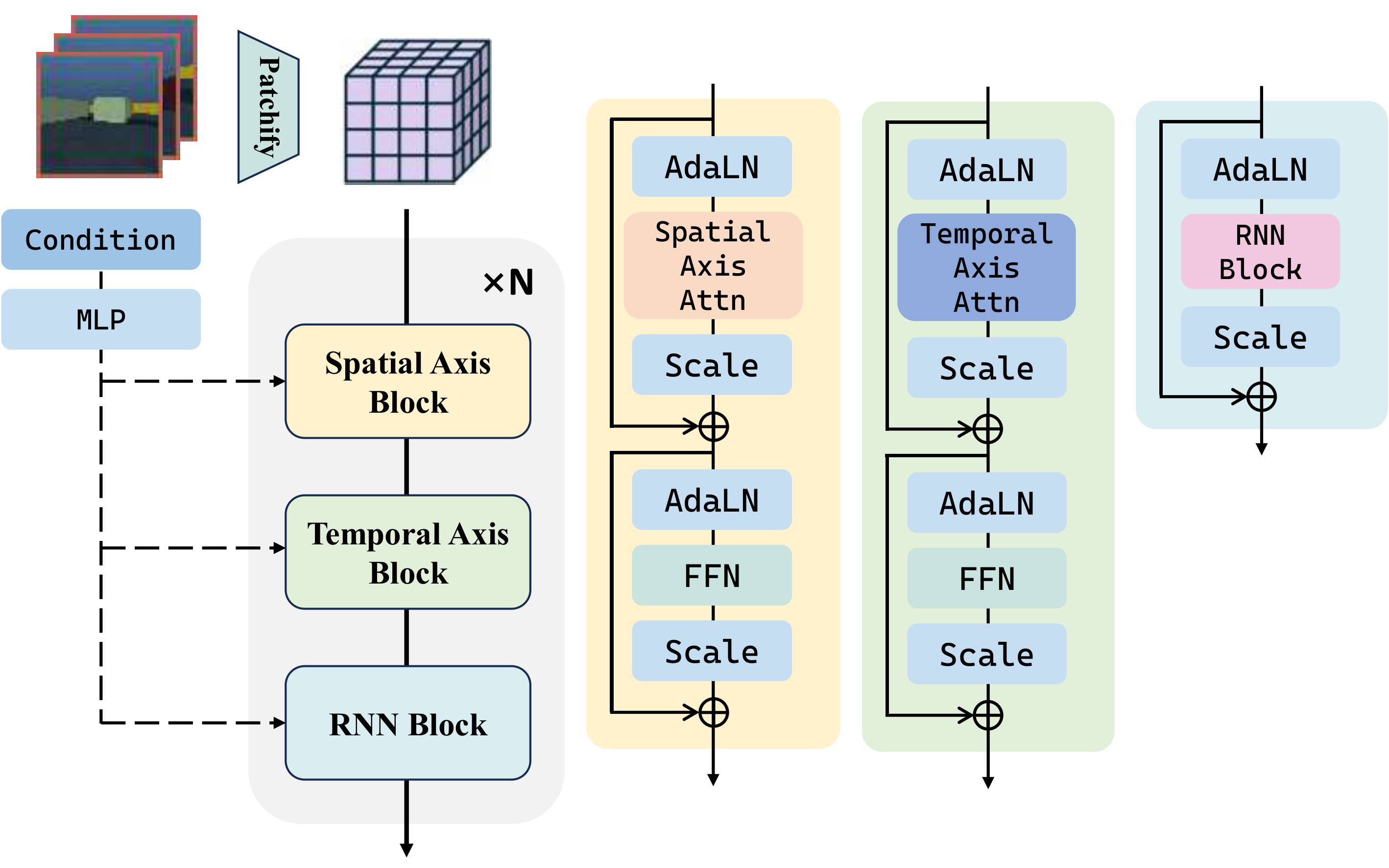
Taiye Chen, Zihan Ding, Anjian Li, Christina Zhang, Zeqi Xiao, Yisen Wang, Chi Jin European Conference on Computer Vision (ECCV) 2026 [Paper] | |
| LLM Economist: Large Population Models and Mechanism Design in Multi-Agent Generative Simulacra
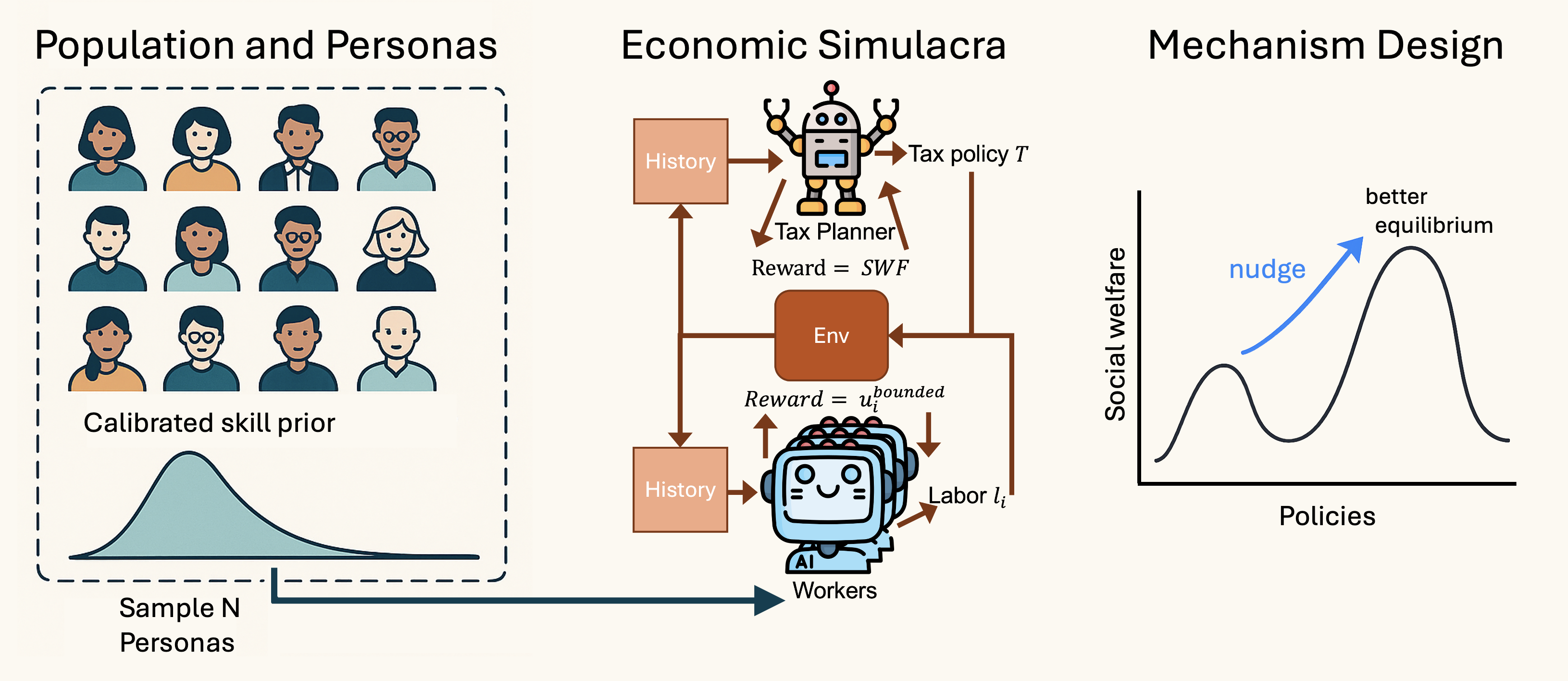
Seth Karten, Wenzhe Li, Zihan Ding, Samuel Kleiner, Yu Bai, Chi Jin Conference on Neural Information Processing Systems (NeurIPS) 2025 LAW Workshop [Paper][Code] | |
| ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes Zeyuan Chen*, Qiyang Yan*, Yuanpei Chen*, Tianhao Wu, Jiyao Zhang, Zihan Ding, Jinzhou Li, Yaodong Yang, Hao Dong (Oral) Conference on Robot Learning (CoRL) 2025 [Paper][Website] | |
| VRAG: Learning World Models for Interactive Video Generation Taiye Chen*, Xun Hu*, Zihan Ding*, Chi Jin Conference on Neural Information Processing Systems (NeurIPS) 2025 [Paper][Website] | |
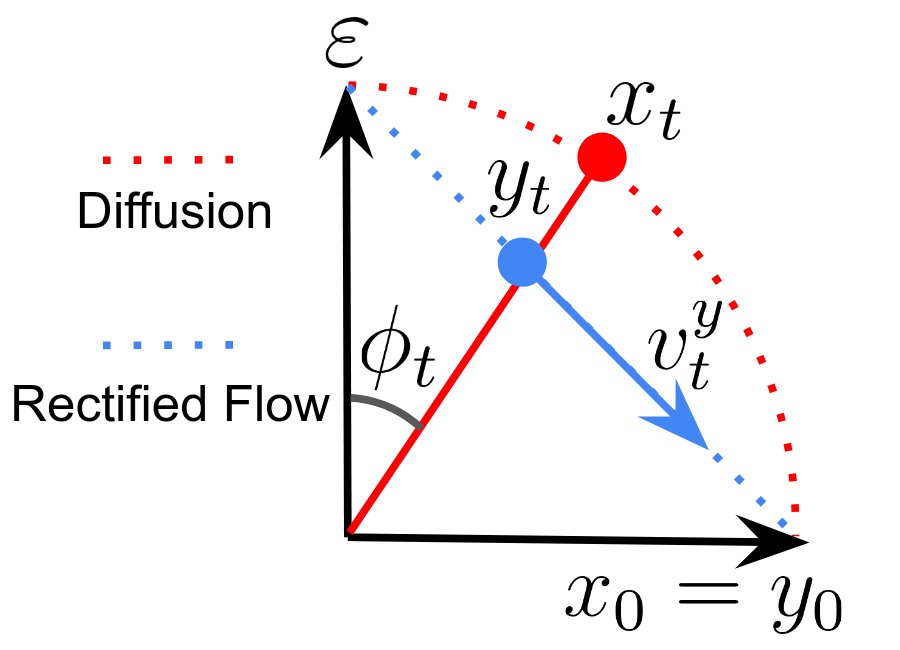
| Generative Diffusion Modeling: A Practical Handbook Zihan Ding, Chi Jin [Paper] | |
| DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization Zihan Ding, Chi Jin, Difan Liu, Haitian Zheng, Krishna Kumar Singh, Qiang Zhang, Yan Kang, Zhe Lin, Yuchen Liu International Conference on Computer Vision (ICCV) 2025 [Paper][Website] | |
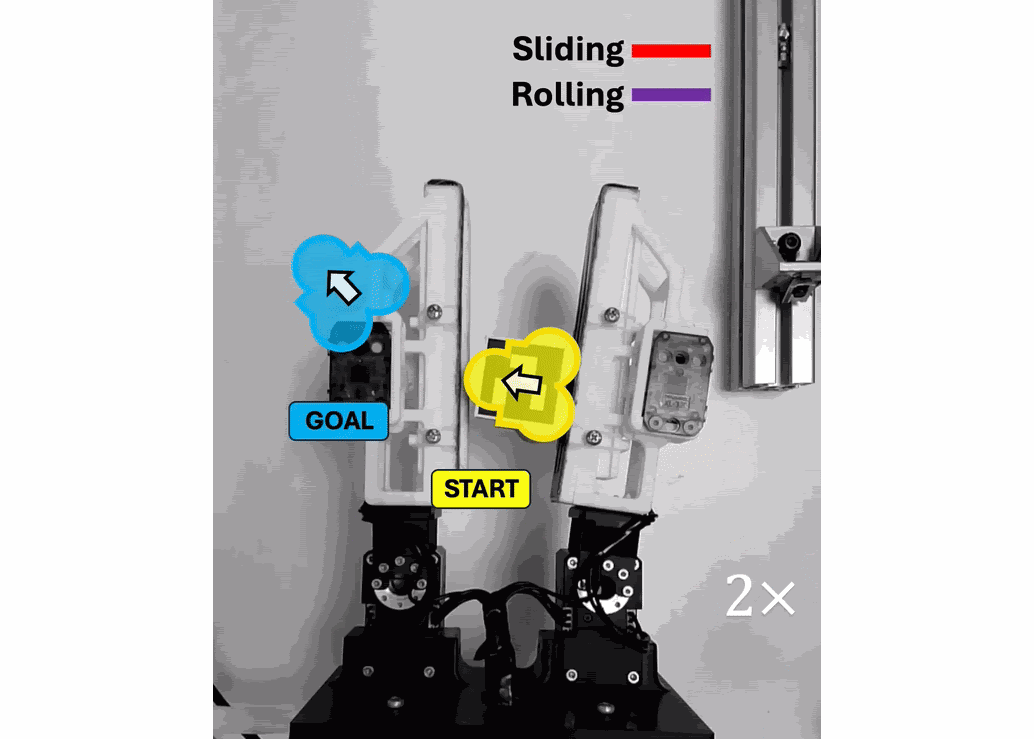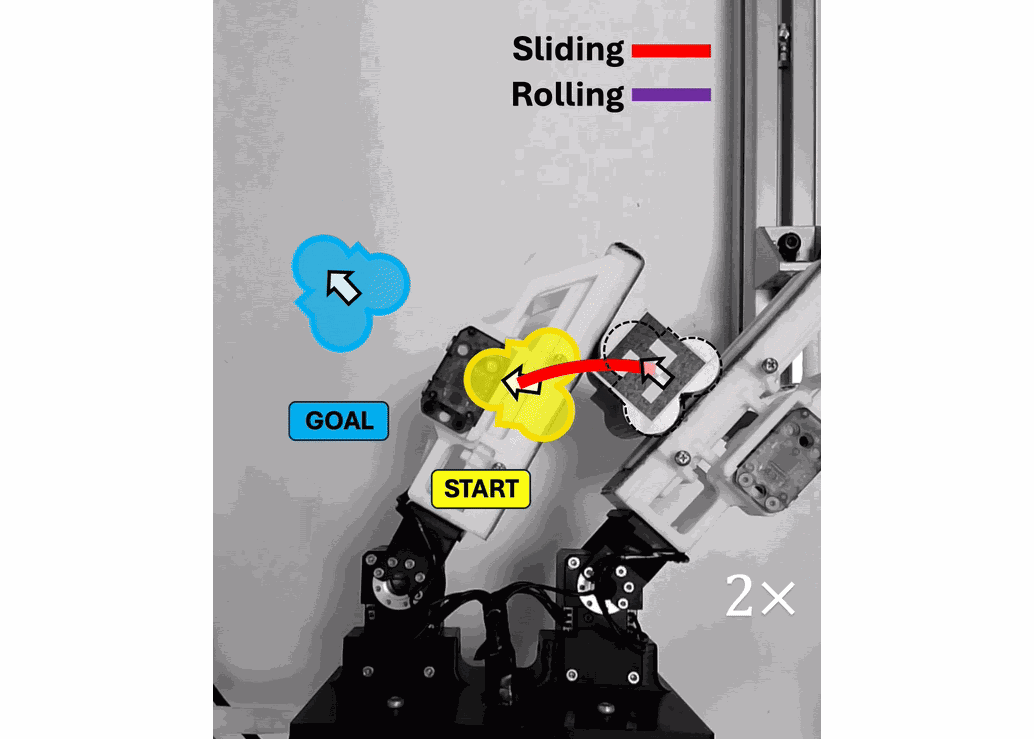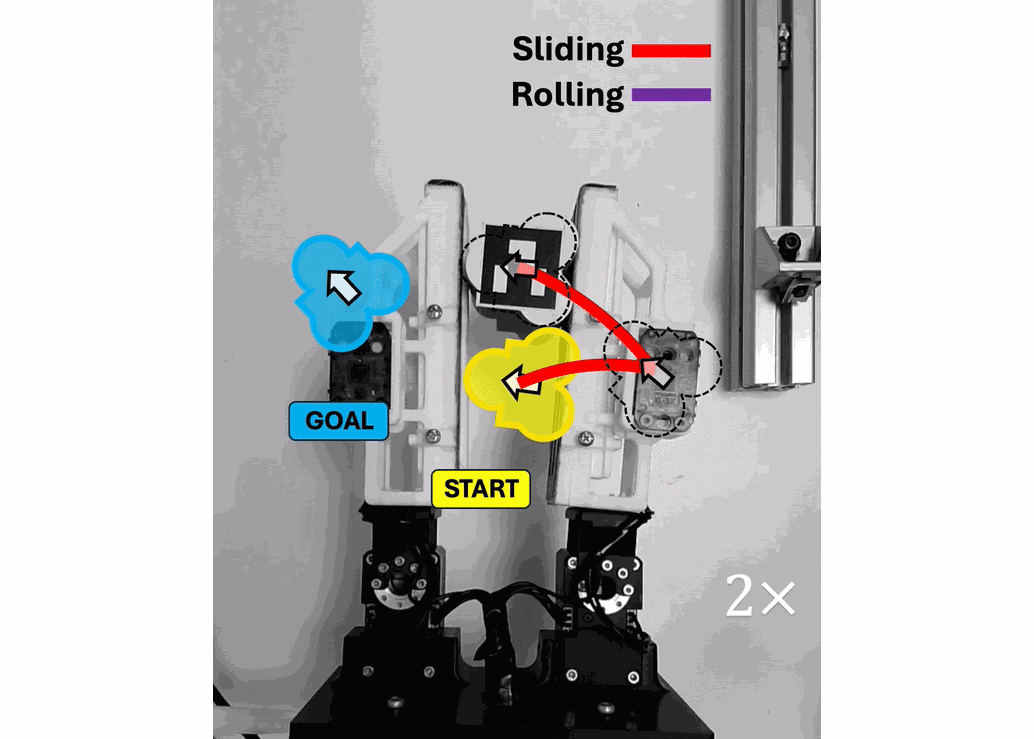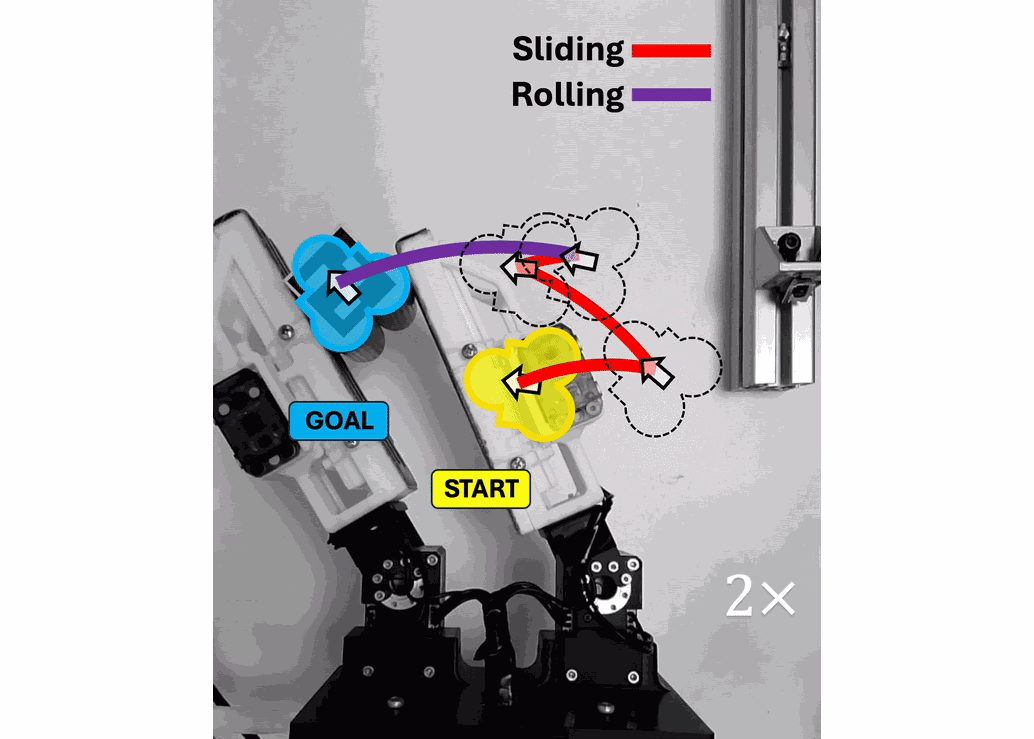
| Variable-Friction In-Hand Manipulation for Arbitrary Objects via Diffusion-Based Imitation Learning Qiyang Yan, Zihan Ding, Xin Zhou, Adam J. Spiers International Conference on Robotics and Automation (ICRA) 2025 [Paper][Website] | |
| Reinforcement Learning in High-frequency Market Making Yuheng Zheng, Zihan Ding [Paper][Code] | |
| How to Beat a Bayesian Adversary Zihan Ding, Kexin Jin, Jonas Latz, Chenguang Liu (alphabetic order) European Journal of Applied Mathematics 2025 [Paper] | |
| FightLadder: A Benchmark for Competitive Multi-Agent Reinforcement Learning Wenzhe Li, Zihan Ding, Seth Karten, Chi Jin The 12th International Conference on Learning Representations (ICLR) 2024 AGI Workshop The 41st International Conference on Machine Learning (ICML) 2024 [Paper][Website][Code] | |
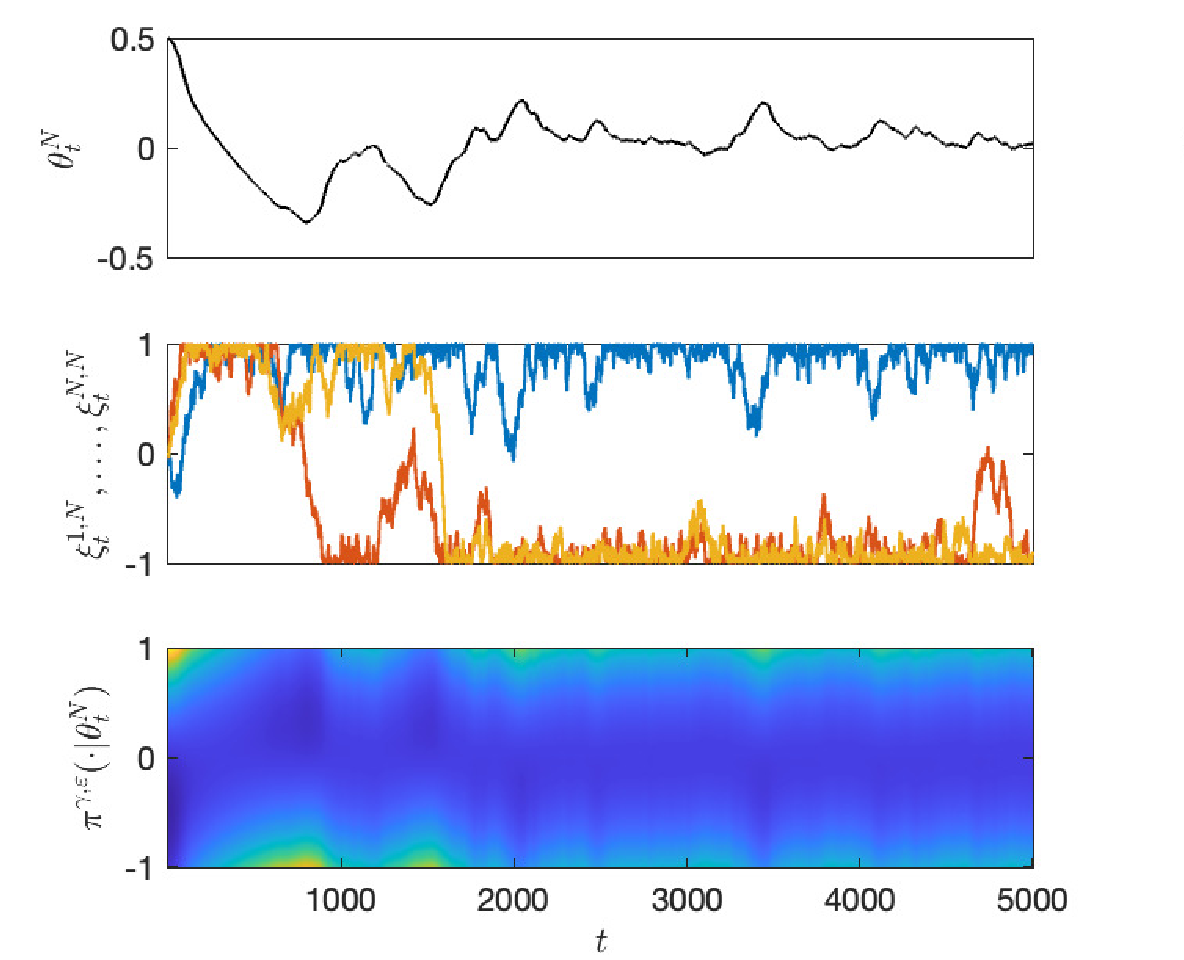
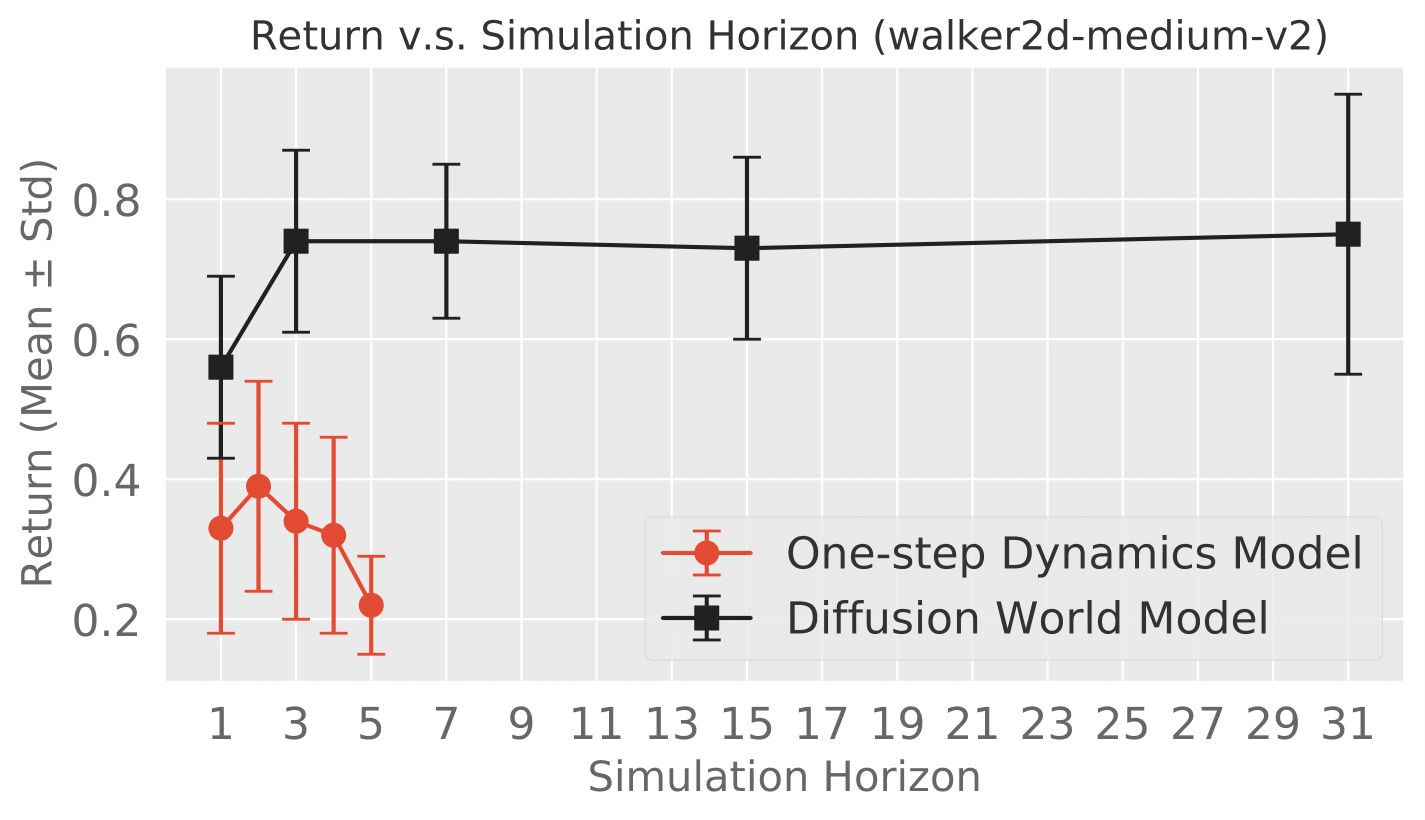
| Diffusion World Model Zihan Ding, Amy Zhang, Yuandong Tian, Qinqing Zheng The 12th International Conference on Learning Representations (ICLR) 2024 GenAI4DM Workshop [Paper][Code] | |
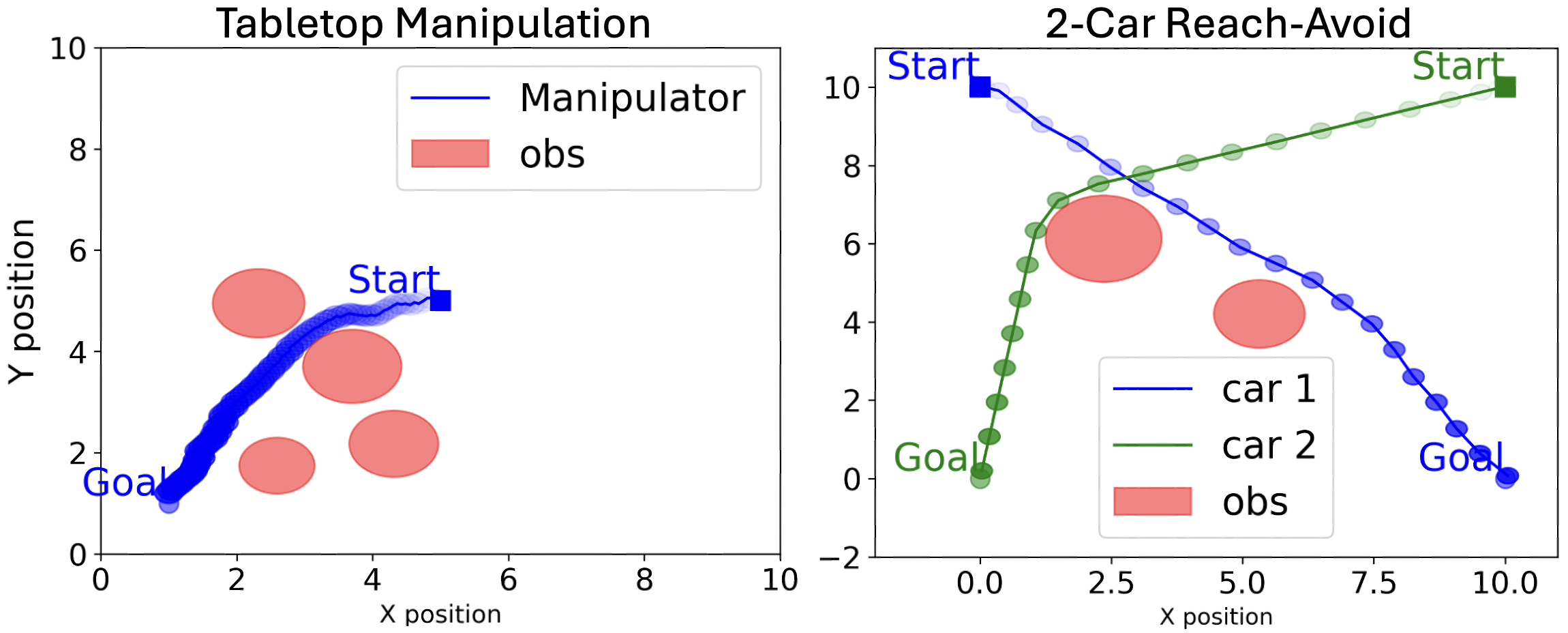
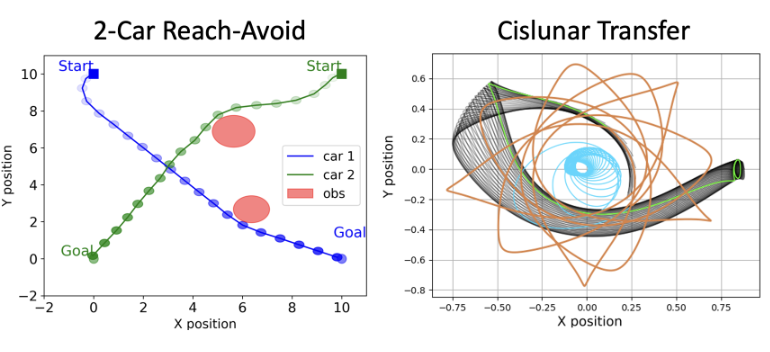
| Constraint-Aware Diffusion Models for Trajectory Optimization Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson The 5th International Conference on Dynamic Data Driven Applications Systems (DDDAS) 2024 [Paper] | |
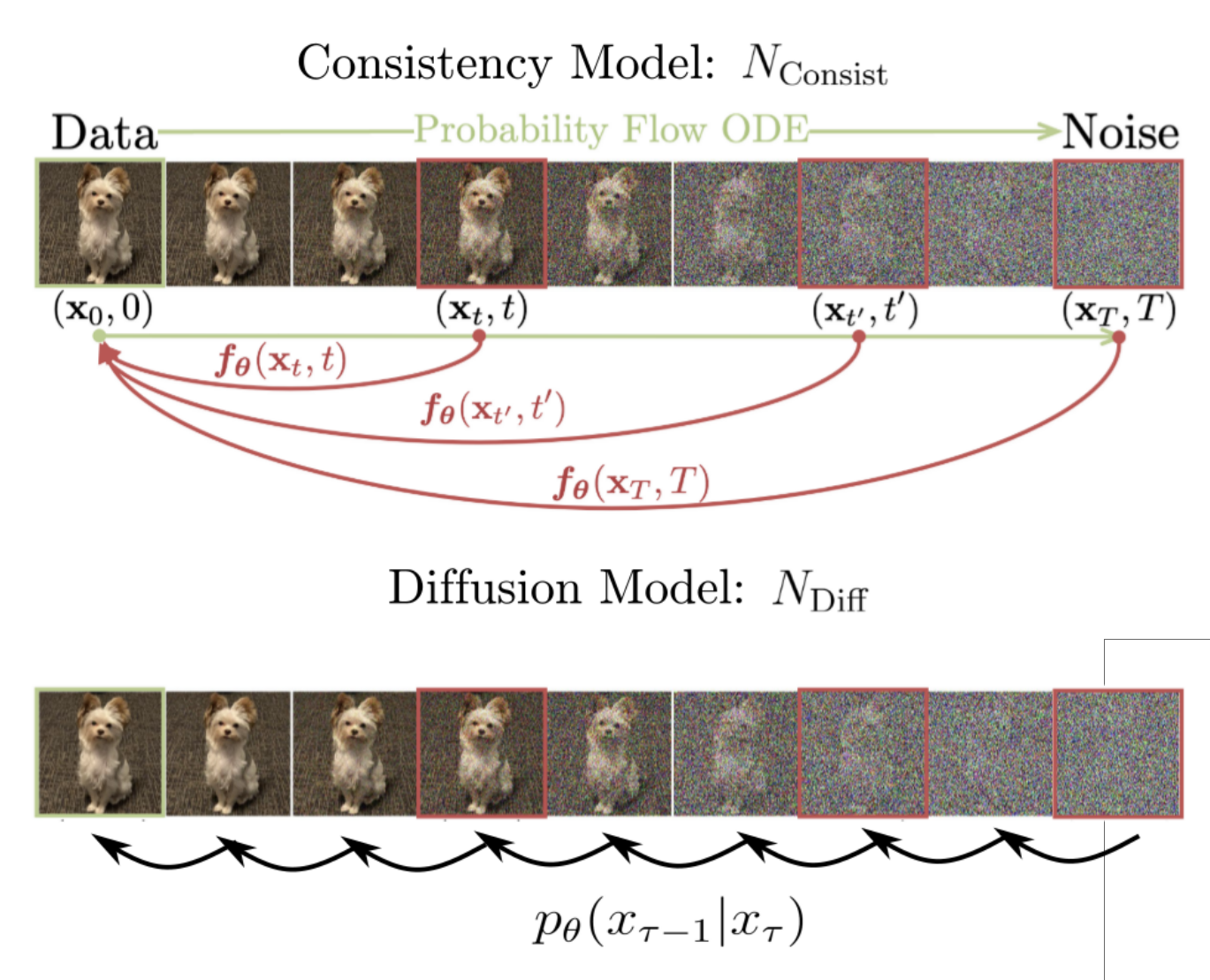
| Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning Zihan Ding, Chi Jin The 12th International Conference on Learning Representations (ICLR) 2024 [Paper][Code] | |
| Efficient and Guaranteed-Safe Non-Convex Trajectory Optimization with Constrained Diffusion Model Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson The 12th International Conference on Learning Representations (ICLR) 2024 GenAI4DM Workshop Learning for Dynamics and Control Conference (L4DC) 2025 [Paper] | |
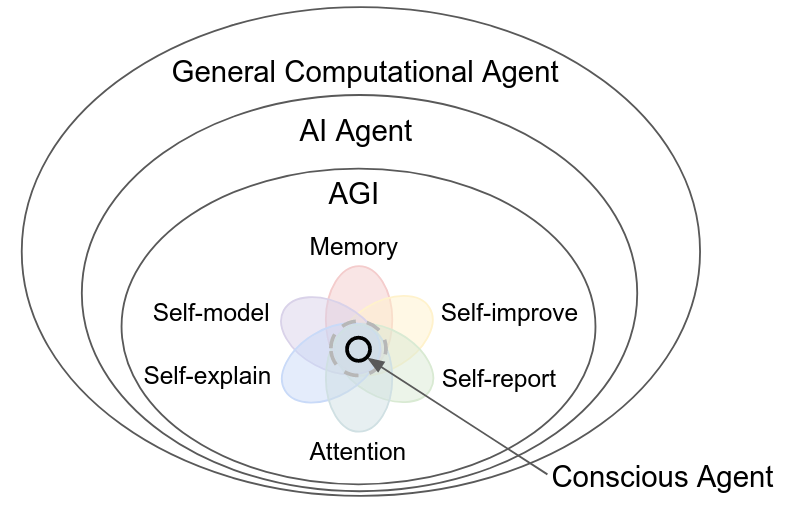
| Survey of Consciousness Theory from Computational Perspective: At the Dawn of Artificial General Intelligence Zihan Ding*, Xiaoxi Wei*, Yidan Xu* [Paper] | |
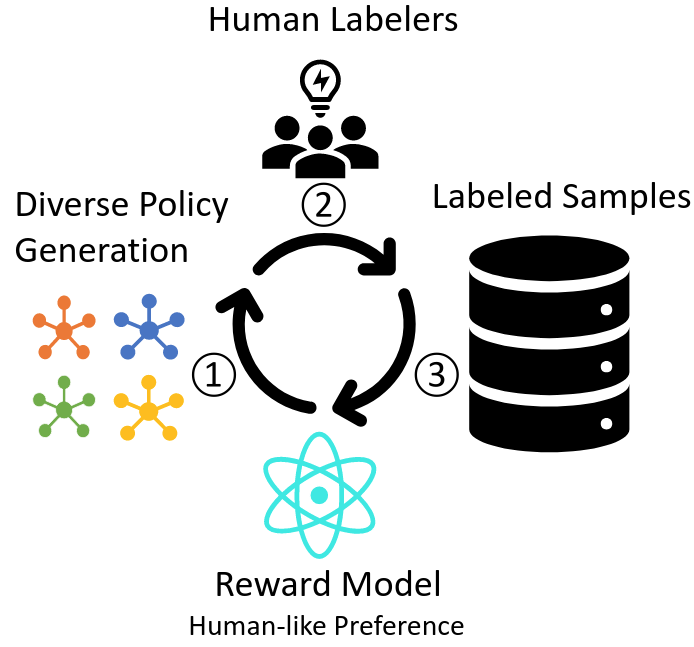
| Learning a Universal Human Prior for Dexterous Manipulation from Human Preference Zihan Ding, Yuanpei Chen, Allen Z. Ren, Shixiang Shane Gu, Hao Dong, Chi Jin Robotics Science and Systems (RSS) 2023 Workshop on Learning Dexterous Manipulation [Paper][Website] | |
| Representation Learning for Low-rank General-sum Markov Games Chengzhuo Ni, Yuda Song, Xuezhou Zhang, Zihan Ding, Chi Jin, Mengdi Wang The 11th International Conference on Learning Representations (ICLR) 2023 [Paper] | |
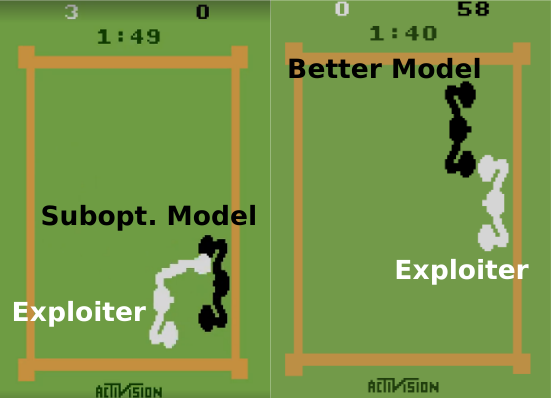
| A Deep Reinforcement Learning Approach for Finding Non-Exploitable Strategies in Two-Player Atari Games Zihan Ding*, Dijia Su*, Qinghua Liu, Chi Jin [Paper][Code1][Code2][Slide] | |
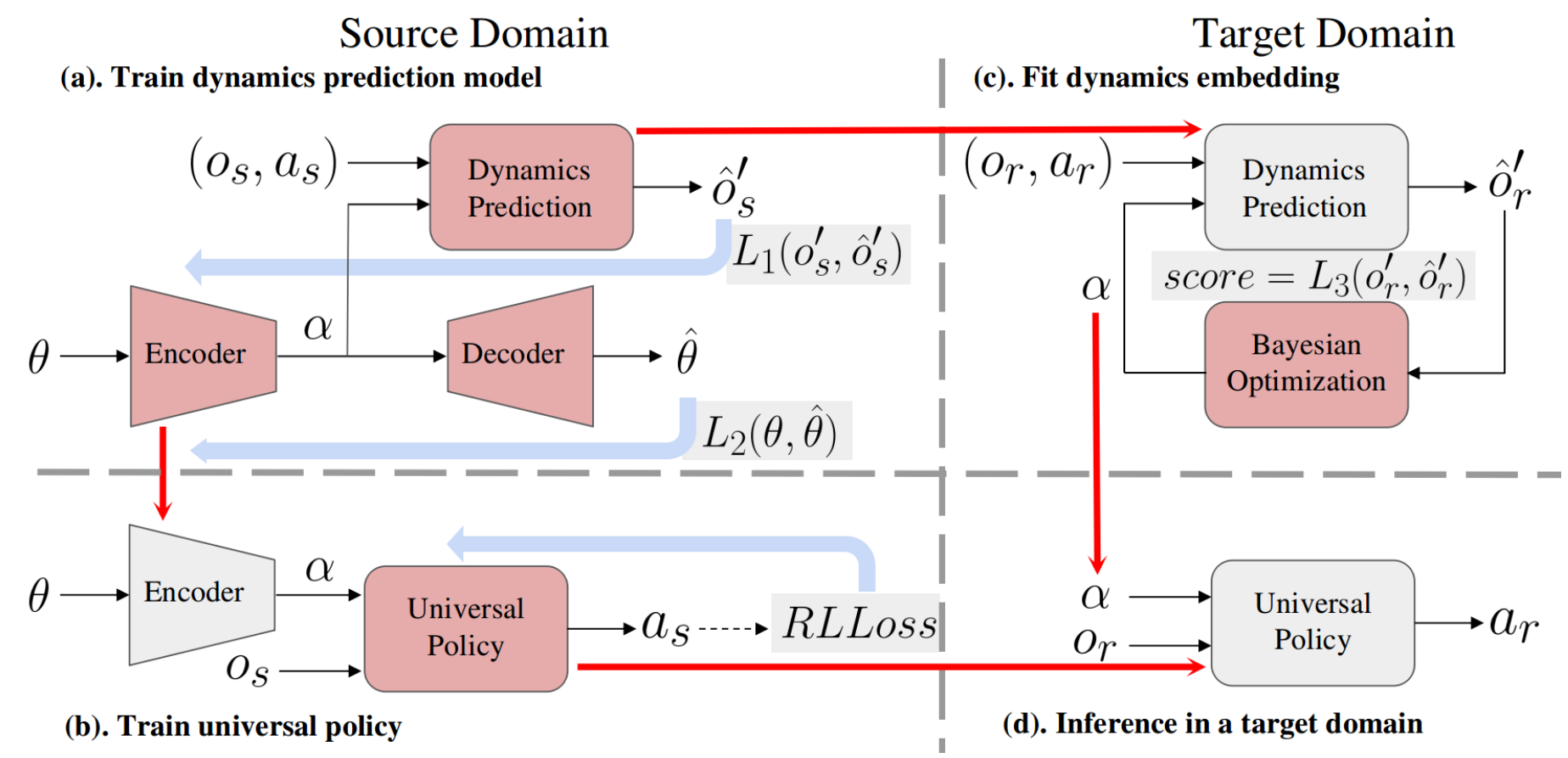
| Not Only Domain Randomization: Universal Policy with Embedding System Identification Zihan Ding Robotics Science and Systems (RSS) 2023 Interdisciplinary Exploration of Generalizable Manipulation Policy Learning: Paradigms and Debates Workshop [Paper][Code] | |
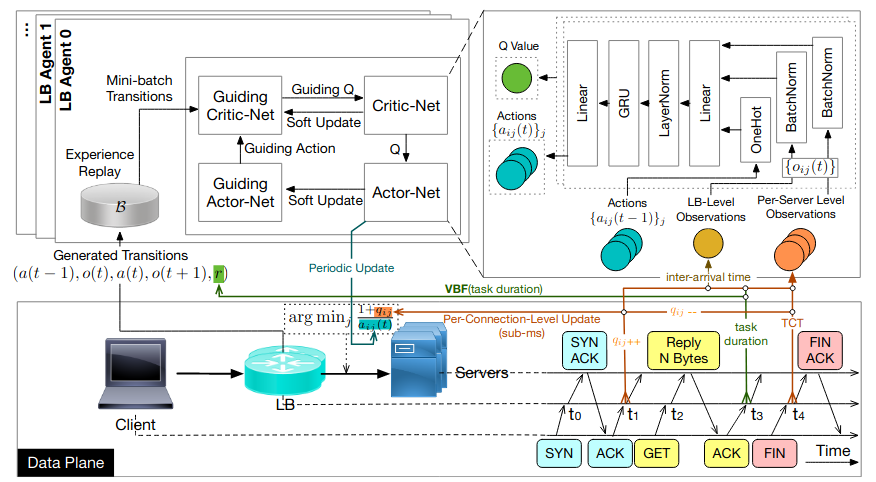
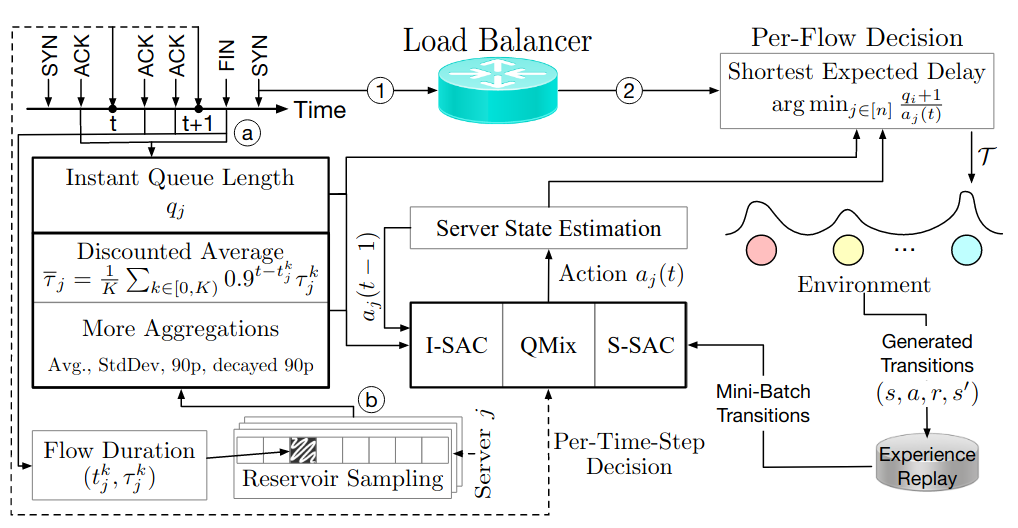
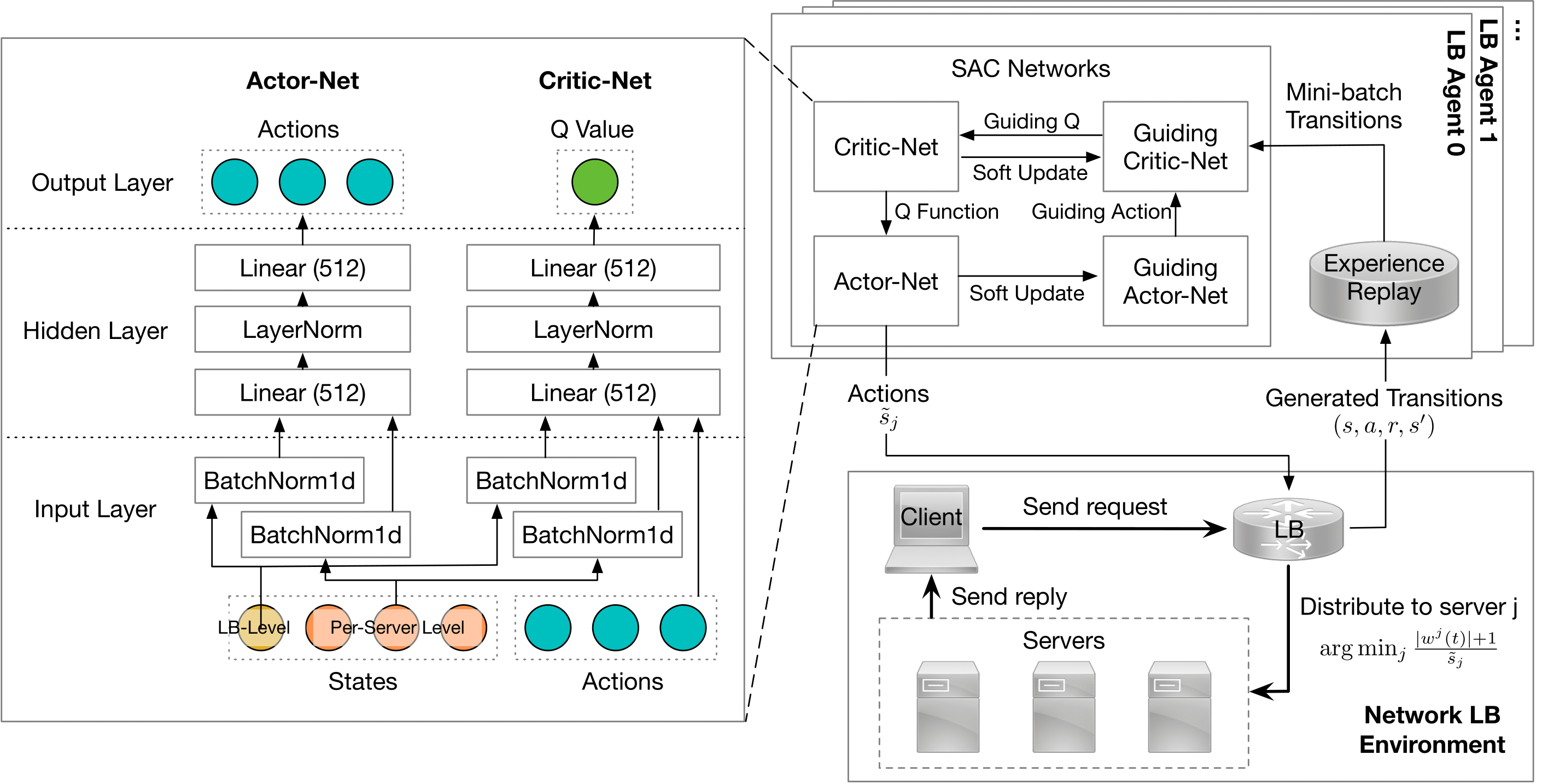
| Learning Distributed and Fair Policies for Network Load Balancing as Markov Potential Game Zhiyuan Yao*, Zihan Ding* 36th Conference on Neural Information Processing Systems (NeurIPS) 2022 [Paper][Code] | |
| Multi-Agent Reinforcement Learning for Network Load Balancing in Data Center Zhiyuan Yao, Zihan Ding and Thomas Heide Clausen 31th ACM International Conference on Information and Knowledge Management (CIKM) 2022 [Paper][Code] | |
| Reinforced Workload Distribution Fairness Zhiyuan Yao, Zihan Ding and Thomas Heide Clausen Machine Learning for Systems at 35th Conference on Neural Information Processing Systems (NeurIPS) 2021. [Paper][Code] | |
| Probabilistic Mixture-of-Experts for Efficient Deep Reinforcement Learning Jie Ren, Yewen Li, Zihan Ding, Wei Pan, Hao Dong [Paper][Code] | |
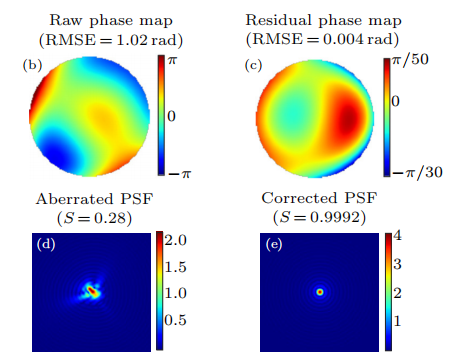
| Bayesian Optimization for Wavefront Sensing and Error Correction Qian Zhong-Hua, Ding Zi-Han, Ai Ming-Zhong, Zheng Yong-Xiang, Cui Jin-Ming, Huang Yun-Feng, Li Chuan-Feng, Guo Guang-Can Chinese Physics Letters 2021. [Paper] | |
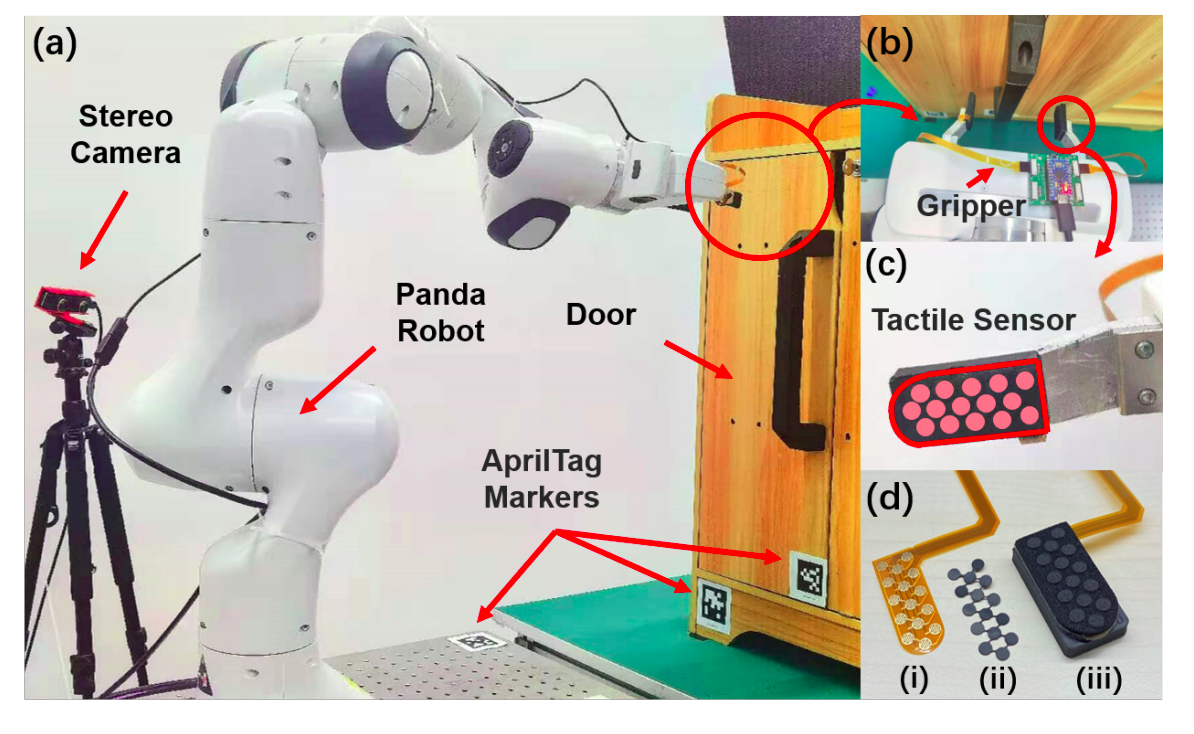
| Sim-to-Real Transfer for Robotic Manipulation with Tactile Sensory Zihan Ding, Ya-Yen Tsai, Wang Wei Lee, Bidan Huang International Conference on Intelligent Robots and Systems (IROS) 2021. [Paper][Code] | |
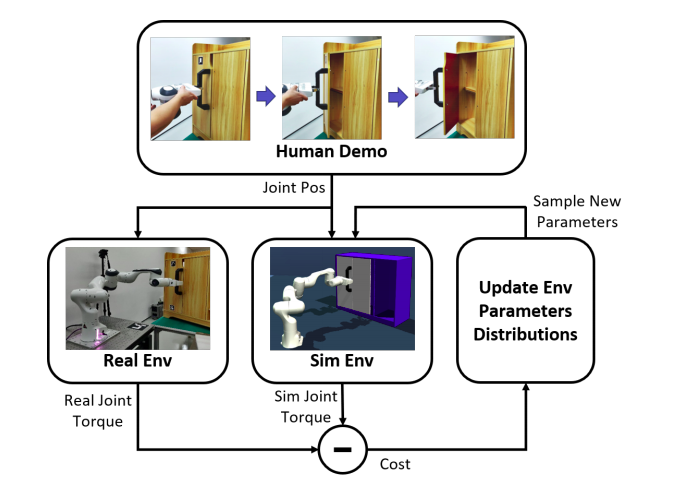
| DROID: Minimizing the Reality Gap using Single-Shot Human Demonstration Ya-Yen Tsai, Hui Xu, Zihan Ding, Chong Zhang, Edward Johns, Bidan Huang IEEE Robotics and Automation Letters (RA-L) 2021. [Paper] | |
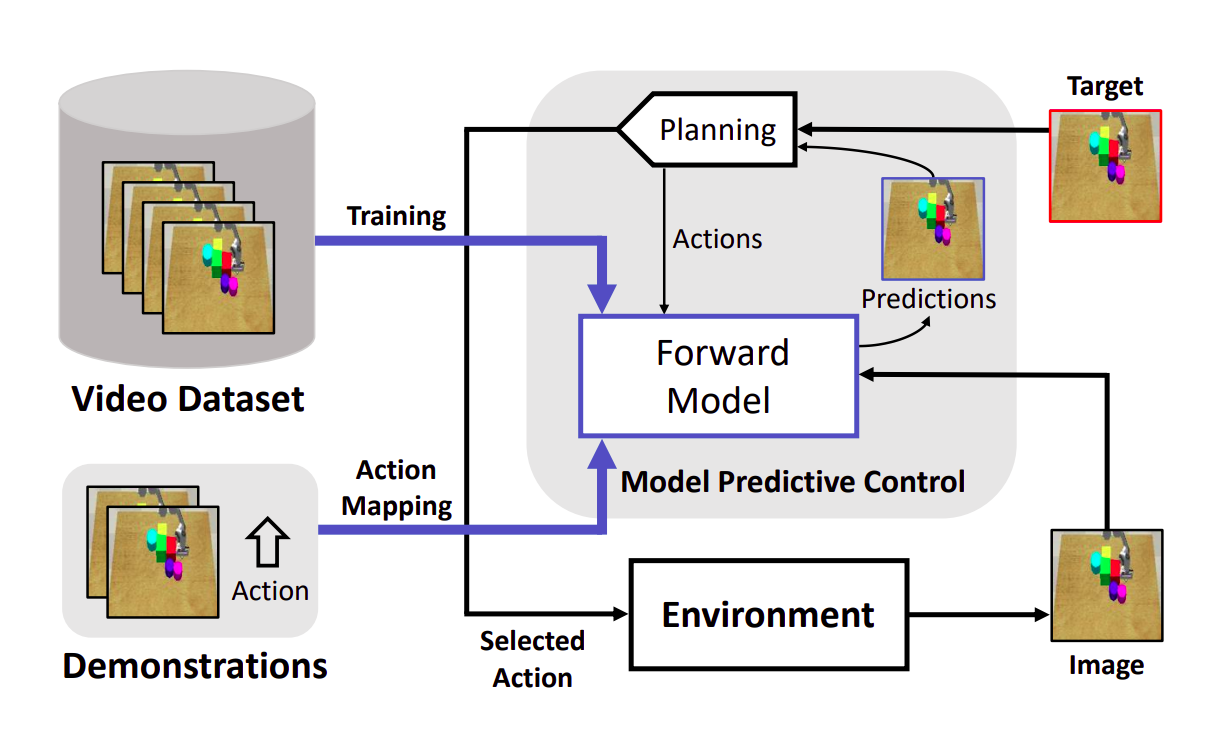
| Robotic Visuomotor Control with Unsupervised Forward Model
Learned from Videos Haoqi Yuan, Ruihai Wu, Andrew Zhao, Haipeng Zhang, Zihan Ding, Hao Dong International Conference on Intelligent Robots and Systems (IROS) 2021. [Paper][Website] | |
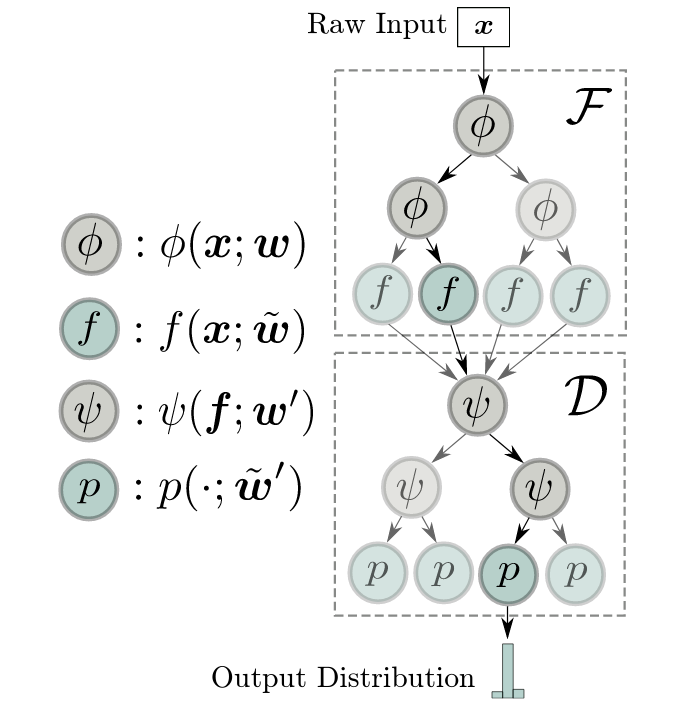
| CDT: Cascading Decision Trees for Explainable Reinforcement Learning Zihan Ding, Pablo Hernandez-Leal, Gavin Weiguang Ding, Changjian Li, Ruitong Huang [Paper][Code] | |
| RLzoo: A Comprehensive and Adaptive Reinforcement Learning Library Zihan Ding, Tianyang Yu, Yanhua Huang, Hongming Zhang, Guo Li, Quancheng Guo, Luo Mai and Hao Dong ACM Multimedia Open Source Software Competition 2021. [Paper][Repo] | |
| Crossing The Gap: A Deep Dive into Zero-Shot Sim-to-Real Transfer for Dynamics Eugene Valassakis, Zihan Ding and Edward Johns International Conference on Intelligent Robots and Systems (IROS) 2020. [Paper][Website][Video] | |
| Sim-to-Real Transfer for Optical Tactile Sensing Zihan Ding, Nathan F. Lepora and Edward Johns International Conference on Robotics and Automation (ICRA) 2020. [Paper][Website][Video] | |
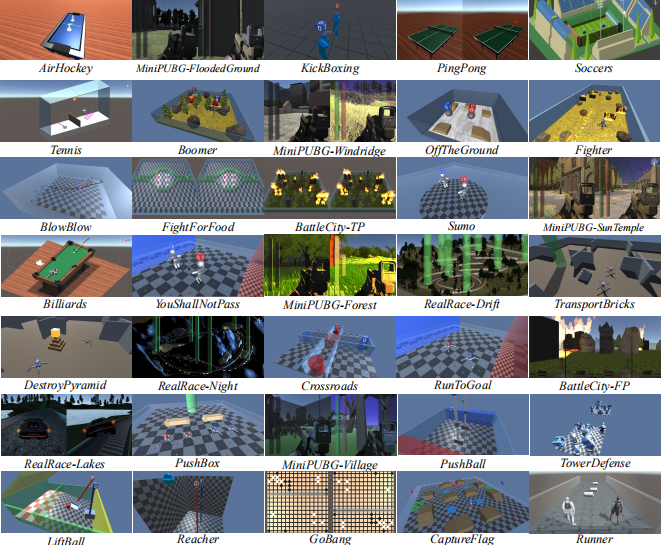
| Arena: A General Evaluation Platform and Building Toolkit for Multi-Agent Intelligence Yuhang Song, Jianyi Wang, Thomas Lukasiewicz, Zhenghua Xu, Mai Xu, Zihan Ding, and Lianlong Wu The Thirty-Fourth AAAI Conference on Artificial Intelligence 2020. [Paper][Code] | |
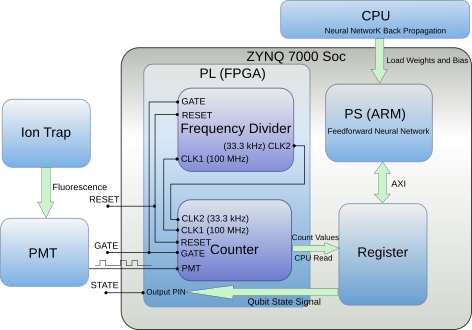
| Fast and High-Fidelity Readout of Single Trapped-Ion Qubit via Machine-Learning Methods Zihan Ding, Jinming Cui, Yunfeng Huang, Chuanfeng Li, Tao Tu, Guangcan Guo Physical Review Applied 2019. [Paper] [Code] | |
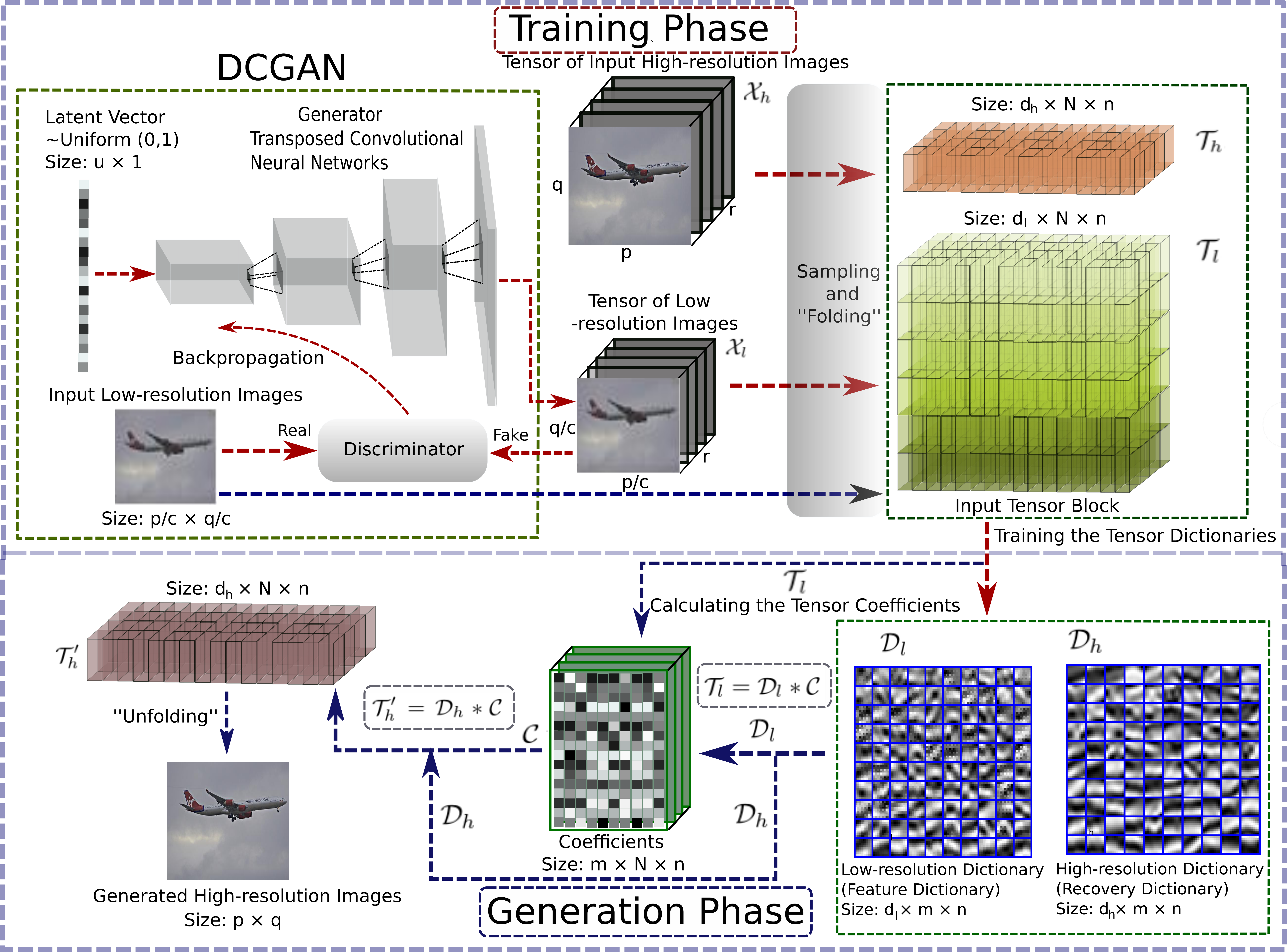
| Tensor Super-Resolution with Generative Adversarial Nets: A Large Image Generation Approach Zihan Ding, Xiao-Yang Liu, Miao Yin International Joint Conference on Artificial Intelligence, Human Brain Artificial Intelligence 2019. [Paper] [Code] | |
| Deep Reinforcement Learning for Intelligent Transportation Systems Xiao-Yang Liu, Zihan Ding, Sem Borst, Anwar Walid NeurIPS Workshop on Machine Learning for Intelligent Transportation Systems 2018. [Paper] [Code] |





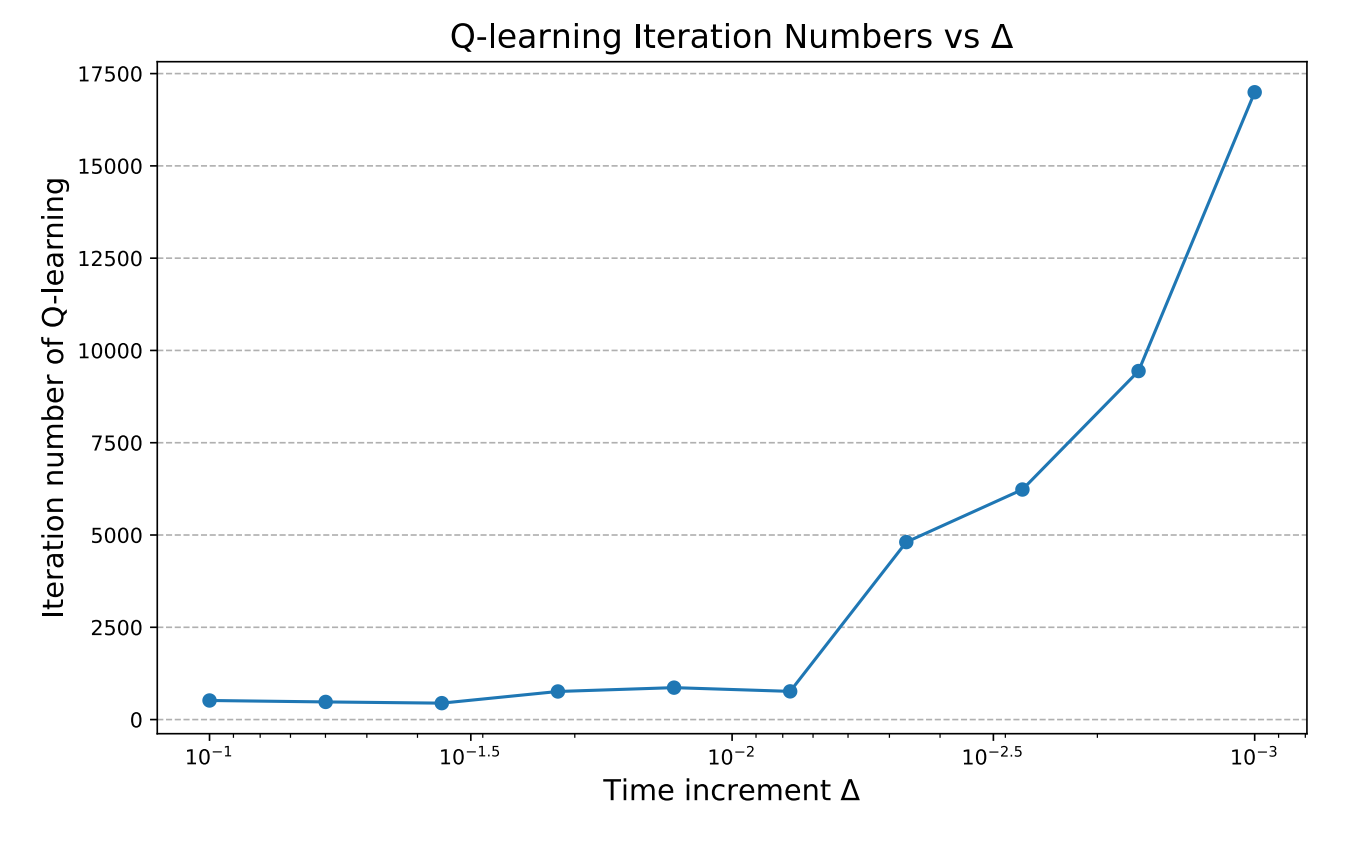





Open Source Projects
TensorLayer Reinforcement Learning Tutorials are hands-on examples of implementing DRL algorithms with TensorLayer, each example is self-contained with simple structure, particularly suitable for novices.
PyTorch implementation of some popular model-free reinforcement learning algorithms.
RLzoo is a collection of the most practical reinforcement learning algorithms, frameworks and applications. It is implemented with Tensorflow 2.0 and API of neural network layers in TensorLayer 2, to provide a hands-on fast-developing approach for reinforcement learning practices and benchmarks.
MARS is a library for multi-agent RL on Markov games, like PettingZoo Atari, SlimeVolleyBall, etc.
Robot Learning Library is a collorative, open-source library for robot learning, mainly using techniques like deep reinforcement learning, robotics simulation, computer vision.
AI community has accumulated an open-source code ocean over the past decade. Applying these intellectual and engineering properties to finance will initiate a paradigm shift from the conventional trading routine to an automated machine learning approach, even RLOps in finance.